Reactor 模式
IO
IO 通常是现今计算机运行中最慢的操作,无论是读取文件还是网络传输。一次内存的读取花费的时间在纳秒级,而读取磁盘上的文件通常花费的时间在毫秒级。对于 CPU 来说,IO 操作它通常会导致操作的延时。
Blocking I/O
在传统的阻塞式 IO 编程中,一次包含 IO 请求的函数调用会阻塞整个线程,直到 IO 操作完成,这通常导致一个函数的操作时间过长。在这种模式下,任何有关 IO 的操作都会使得线程阻塞,这些操作包括读取 socket,发送 socket,读取文件,写文件等等。总而言之,在一次请求处理中,线程可能会阻塞很多次。所以这种模式下,显然单个线程无法同时处理多个网络请求。
因此,在几十年前的服务器编程中,传统的方式是为每个到来的网络连接开启一个线程(或者从线程池中取一个空闲线程),这样单个请求的读取过程即使阻塞了一个线程,也不会影响其他请求的处理。如果线程过多,线程的调度会加重 CPU 的负担,并带来上下文切换的开销。
Non-blocking I/O
非阻塞 IO 模式下,涉及 IO 的系统调用总是立即返回。如果在调用时数据未就绪,则调用会返回一个预定义的值,表示当前数据未准备好。
例如,在 Unix 系统中,
fcntl()函数可以用来控制一个已有的文件操作符,将其的读写模式改变为非阻塞(用O_NONBLOCK标志位)。一旦文件操作在非阻塞模式下,如果该文件还没有数据可读,则读操作会返回EAGAIN。
最基本的使用非阻塞 IO 的编程范式是在一个循环里不断地轮询相应接口,直到有数据返回——这被称为忙等待。下面的伪代码展示了这一逻辑:
1 | resources = [socketA, socketB, pipeA]; |
这么简单的代码已经可以在单线程里面处理多个 IO 资源的读写了,但还不够高效。事实上,在上面的例子中,忙等待会浪费很多 CPU 时间——因为大多数时候资源都是不可用的。我们希望等到资源可用的时候能够自动通知线程,而不是线程一直循环着浪费 CPU 资源。
Event Demultiplexing
忙等待不是处理非阻塞 IO 的理想策略,不过现代操作系统提供了原生高效的非阻塞 IO 的 API,称为 synchronous event demultiplexer,或者 event notification interface。这种机制下,多个资源会被置于监视之下,一旦有资源可用,则添加对应的 event 到一个队列下,如果这些资源均不可用,接口会阻塞。
1 | socketA, pipeB; |
[1] 只要有资源是可读的,watch
函数就会返回,一旦无资源可读,就会阻塞。 [2]
在循环中,我们遍历可读的事件。 [3]
因为数据已经准备好了,read 函数将会立即返回数据。
后续就是程序的业务逻辑,这就被称为事件循环(event loop)。现在我们可以很从容地从忙等待中解放出来。在数据没有就绪时,线程是阻塞的,不会占用 CPU 资源,当线程被唤醒时,就代表着有数据就绪。
Reactor Pattern
Reactor 模式是上一节的算法进一步优化的结果。主要思想是让每一个 IO 事件对应一个 handler。在 event loop 中一旦该事件被触发,就调用对应的 handler(通常以回调函数的形式定义)进行处理。
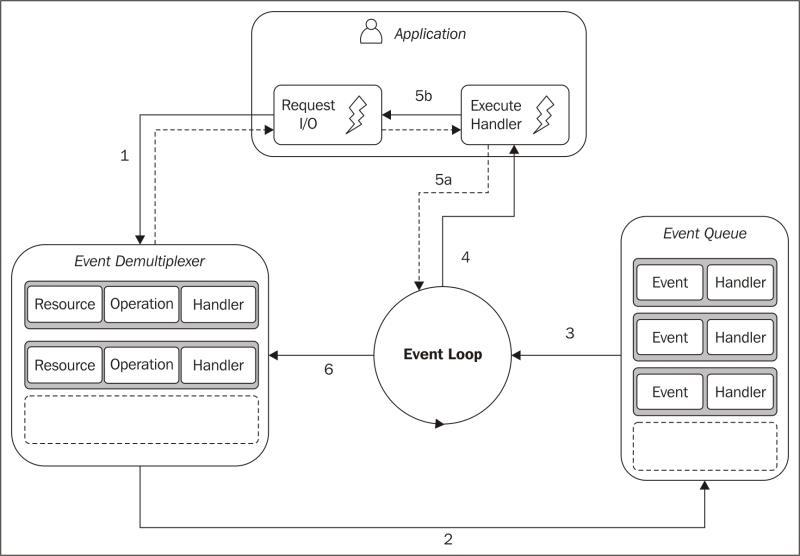
- 应用把接收到的网络请求提交到 event demultiplexer,同时定义对应的 handler 函数。这一操作会立即返回。
- 当一系列 IO 操作完成后,事件被 push 到事件队列。
- 事件循环处理到达的事件。
- 每个事件都会调用对应的 handler 进行处理。
- handler 函数一旦执行完成,就会把控制权返回事件循环。在 handler 中,例如 Web 服务器,通常会在处理完成后返回一些数据给客户端,这是新的 I/O 事件,需要添加到 event demultiplexer(5b)后,才把控制权返回事件循环(5a)。
- 当事件队列处理完为空后,单次循环结束,继续下一次事件循环处理。
Multi-Reactor Pattern
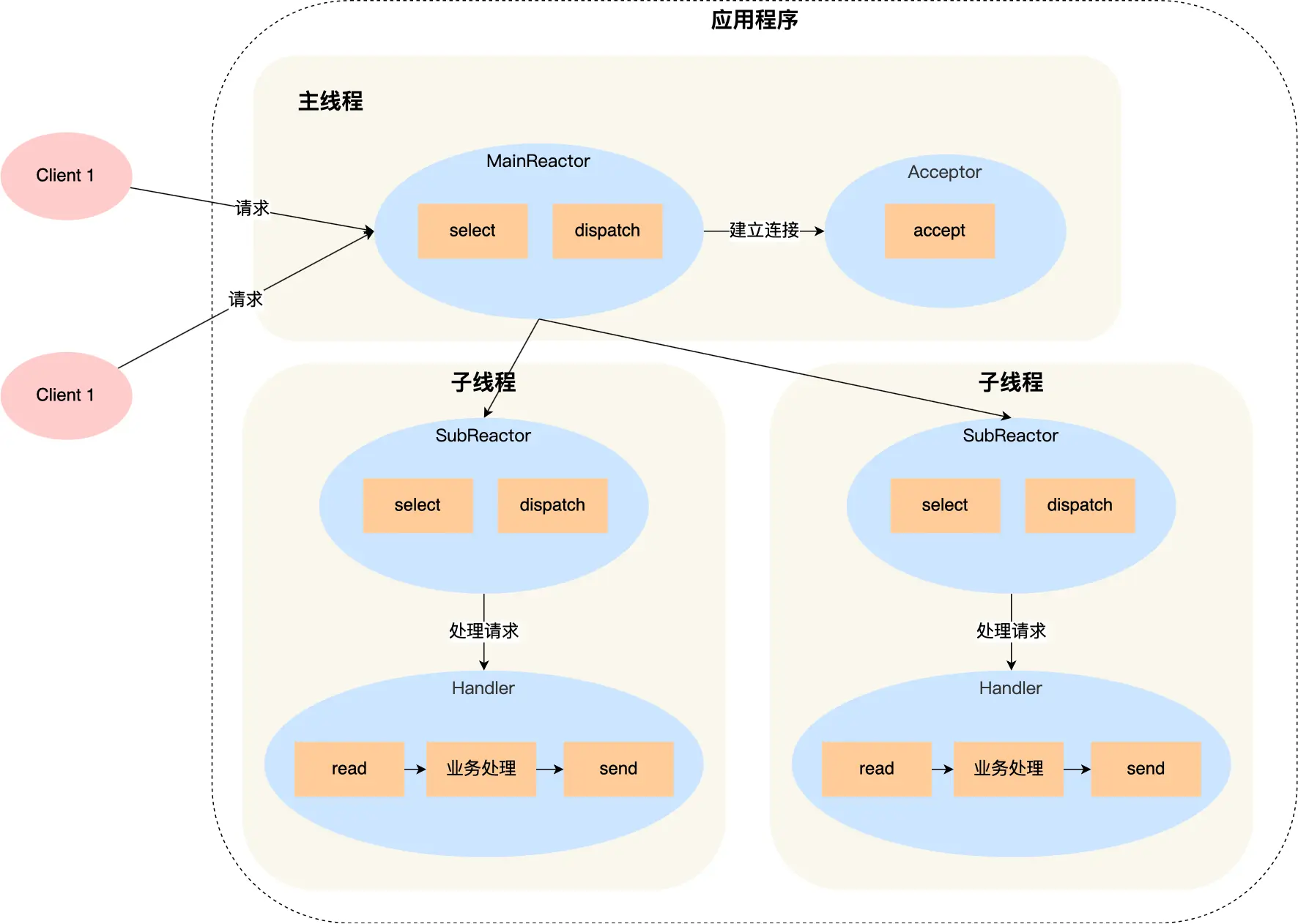
「单 Reactor」的模式依然存在问题:一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈。于是就诞生出了「多 Reactor」模式。
- 主线程只负责接收新连接。
- 子线程负责完成后续的业务处理。
相当于将主线程的部分任务下放到了子线程中,使主线程成为瓶颈的机会少了一些。
Higher Abstraction
每个操作系统都实现了自己的 Event Demultiplexer ,在 Linux 上为 epoll,Mac OS X上为 kqueue,Windows 上为 I/O Completion Port API(IOCP)。除此之外,对于不同类型的资源,其 IO 操作的细节不同。
例如,在 Unix 中,普通的文件是不支持非阻塞读写的,因此为了模拟非阻塞的接口行为,我们只能够在事件循环之外开额外的线程去进行读写。